

VEO 3 جدیدترین مدل تولید ویدیو با هوش مصنوعی گوگل است که در سال ۲۰۲۵ توسط تیم DeepMind معرفی شد. این مدل نسل سوم از خانوادهی VEO محسوب میشود و نسبت به نسخهی قبلی، یعنی VEO 2، جهشی چشمگیر در کیفیت تصویر، دقت حرکات و امکان افزودن صدا ایجاد کرده است. در آموزش VEO 3 یاد میگیرید چطور با استفاده از پرامپتهای متنی یا تصویری، تنها در چند ثانیه ویدیوهایی واقعی با گفتار طبیعی (حتی به زبان فارسی) بسازید.
تفاوت VEO 3 با VEO 2 فقط در وضوح ویدیو نیست؛ بلکه حالا میتوانید صدا، افکتهای صوتی و حتی گفتار هماهنگ با حرکت لب را به ویدیو اضافه کنید. این قابلیت، مسیر ساخت ویدیو با هوش مصنوعی را برای تولیدکنندگان محتوا، مدرسان و برندها متحول کرده است.
در این مقاله، تمام قابلیتهای مدل VEO 3 (و VEO 3.1)، مقایسهی آن با نسخهی قبلی، نحوهی استفاده از طریق Gemini و نکات حرفهای پرامپتنویسی را مرحلهبهمرحله بررسی میکنیم تا بتوانید از جدیدترین ابزار گوگل برای تولید ویدیوهای حرفهای بهره بگیرید.
VEO چیست و چه کاربردی دارد؟
(Video-Enabled Omnimodel) VEO سری مدلهای هوش مصنوعی است که توسط گوگل و تیم DeepMind برای تولید ویدیو از متن یا تصویر طراحی شدهاند. هدف اصلی این مدلها راحتی در ساخت ویدئو، عدم نیاز به تجهیزات حرفهای و افزایش سرعت است. در ادامه کاربردهای اصلی VEO را توضیح میدهیم:
- تولید ویدیو از متن: ساخت ویدئو با هوش مصنوعی VEO را میتوان با واردکردن توضیحی کوتاه بهصورت متن در این مدل انجام داد.
- تولید ویدیو از تصویر: با استفاده از VEO، یک عکس ساده میتواند به ویدیوی کوتاه با حرکات و افکتهای طبیعی تبدیل شود.
- همگامسازی صدا و تصویر: با مدل VEO 3 امکان تولید گفتار و افکت صوتی همزمان با تصویر وجود دارد. بنابراین، با این مدل میتوان ویدئوهایی به زبان فارسی ساخت.
- کاربرد در آموزش و محتوا: برای تولید محتوای آموزشی، تبلیغاتی، تیزرهای کوتاه و محتوای شبکههای اجتماعی مناسب است.
- ساخت نمونههایی از ایدهها: طراحان، تولیدکنندگان محتوا و توسعهدهندگان میتوانند ایدههای خود را در قالب ویدیو مشاهده و اصلاح کنند.
برای اینکه در این زمینه اطلاعات بیشتری کسب کنید، پیشنهاد میکنیم مقاله ساخت ویدیو با ابزارهای هوش مصنوعی را مطالعه کنید.

معرفی VEO 2
VEO 2 یکی از مدلهای نسل دوم ویدیوساز گوگل است که در سال ۲۰۲۴ معرفی شد و پایهگذار مسیر توسعهی مدلهای پیشرفتهتر مانند VEO 3 به شمار میرود. این مدل بخشی از مجموعه ابزارهای Google DeepMind و Google AI Studio است و با هدف تولید خودکار ویدیو از طریق توضیحات متنی طراحی شده است. بااینحال، VEO 2 دارای چند محدودیت مهم است که در ادامه به این محدودیتها اشاره میکنیم:
- عدم پشتیبانی از صدا و گفتار: در VEO 2، خروجی ویدیو فقط به تصویر محدود میشود و امکان اضافهکردن صدا، موسیقی یا گفتار طبیعی وجود ندارد .
- کیفیت معمولی تصویر: هرچند کیفیت ویدیوها در سطح قابل قبولی قرار دارد؛ اما از نظر وضوح، عمق، جزئیات و طبیعیبودن حرکت، عملکرد خیلی خوبی ندارد.
- دسترسی محدود به Google AI Studio: مدل VEO 2 هنوز به Gemini API منتقل نشده و عمدتا از طریق پلتفرم Google AI Studio در دسترس است. در نتیجه، بعضی امکانات کنترلی و صوتی در آن غیرفعال هستند.
بهطور کلی، VEO 2 قدم مهمی در مسیر تکامل مدلهای ویدیوساز گوگل محسوب میشود. این مدل، پایهای برای آموزش و توسعه نسخههای پیشرفتهتر محسوب میشود.
🎬 نمونه ویدیو ساختهشده با VEO 2
VEO 3 چیست و چه امکانات جدیدی دارد؟
VEO 3 نسل سوم مدلهای ویدیوساز گوگل است که با هدف ارتقای کیفیت و قابلیتهای تولید ویدیوهای هوش مصنوعی عرضه شد. این مدل نسبت به نسخههای قبلی خود، امکانات بیشتری ارائه میدهد و دنیای تولید ویدئو را کاملا متحول کرد. VEO 3 در حال حاضر میتواند ویدیوهای واقعگرایانه با کیفیت بالا، همراه با صدا و گفتار طبیعی تولید کند و حتی از زبان فارسی هم پشتیبانی میکند. از امکانات کلیدی این مدل میتوانیم به موارد زیر اشاره کنیم:
1. اضافه کردن صدا در VEO 3
این مهمترین قابلیت VEO 3 محسوب میشود و آن را از نسخههای قبلی متمایز میکند. این مدل میتواند گفتار طبیعی و هماهنگ با حرکت لبها تولید کند و به این صورت ویدئوها واقعیتر میشوند. علاوهبر گفتار، میتوان موسیقی و افکتهای صوتی به ویدیو اضافه کرد تا کاملا طبیعی و حرفهای شود. استفاده از زبان فارسی هنوز محدودیتهایی دارد؛ اما قدم بزرگی در تولید محتوای ویدیویی به زبان غیرانگلیسی محسوب میشود.
2. ساخت ویدئو خبرنگاری با VEO 3
این نسخه قابلیت تولید ویدیوهای کوتاه خبری و اطلاعرسانی را دارد. تولید محتوای خبری با این مدل، علاوهبر سرعت، دقت بالایی در ارائه جزئیات و هماهنگی تصویر و صدا دارد.
3. کیفیت بالاتر تصویر و جزئیات دقیقتر نسبت به VEO 2
این نسخه تصاویری با کیفیت بالاتر و جزئیات دقیقتر نسبتبه نسخه قبلی تولید میکند. نورپردازی، حرکات طبیعی کاراکترها و ترنزیشنها در این نسخه بسیار دقیق شده است. این پیشرفت باعث میشود ویدیوهای تولیدشده حرفهایتر باشند.
4. ساخت تیزر با JSON در VEO 3
یکی از قابلیتهای مهم این نسخه، امکان استفاده از JSON Prompting است. این امکان، VEO3 را برای تولید تیزرها و محتوای تبلیغاتی حرفهای بسیار مناسب میکند و به بازاریابان و تولیدکنندگان محتوا انعطاف بیشتری میدهد.
🎥 نمونه ویدیو ساختهشده با VEO 3
این تیزر تبلیغاتی در مدل VEO 3 با کد جیسون ساخته شده است:
VEO 3.1 و گام بعدی گوگل
گوگل بهتازگی نسخهی جدید مدل ویدیوساز خود را با نام VEO 3.1 معرفی کرده است؛ مدلی که تمرکز آن بر بهبود کیفیت تصویر، افزایش دقت صداگذاری و کنترل دقیقتر بر صحنههاست. این نسخه فعلاً در Gemini Pro فعال شده و نسبت به VEO 3، ثبات بیشتر، انعطاف بالاتر در اجرای پرامپتها و قابلیتهای حرفهایتری در تولید ویدیو دارد.
برخی از ویژگیهای جدید VEO 3.1 عبارتاند از:
- صداگذاری بهینهتر و هماهنگی دقیق لبها با گفتار: در VEO 3.1، مدلهای صوتی گوگل بهروزرسانی شدهاند و تلفظ فارسی طبیعیتر و هماهنگتر با تصویر تولید میشود.
- پشتیبانی از چند صحنه در یک پرامپت (Multi-Scene Prompting): حالا میتوان چند موقعیت یا زاویه مختلف را در یک دستور JSON مشخص کرد تا ویدیو چندبخشی با ترنزیشن نرم تولید شود.
- کیفیت بصری بالاتر (Upgraded Rendering): وضوح تصویر به 4K نزدیک شده و نورپردازی، سایهها و جزئیات چهره طبیعیتر از نسخه قبل است.
- ادغام کامل با Gemini Pro و Gemini API: کاربران حرفهای میتوانند از طریق API، پرامپتهای پیچیدهتر را ارسال کرده و خروجی را برای پروژههای تبلیغاتی یا آموزشی سفارشیسازی کنند.
- پشتیبانی بهتر از زبان فارسی و سایر زبانهای منطقهای: در نسخهی ۳.۱ خطاهای لحن و مکث در گفتار فارسی کاهش یافته و ویدیوهای تولیدشده با صدای طبیعیتر و ریتم روانتری ارائه میشوند.
🎞️ نمونه ویدیو ساختهشده با VEO3.1
جدول تفاوت VEO 2 با VEO 3
در ادامه جدول تفاوت VEO 2 باVEO 3 را شرح میدهیم:
| ویژگی | VEO2 | VEO3 | VEO3.1 |
|---|---|---|---|
| کیفیت ویدیو | خوب، ولی محدود به وضوح متوسط و حرکات مصنوعی | بالاتر، واقعگرایانه، با جزئیات دقیق و حرکات طبیعی | خیلی بالا، نزدیک به 4K با نورپردازی و ترنزیشن طبیعی |
| قابلیت افزودن صدا | ❌ ندارد | ✅ دارد | ✅ گفتار طبیعی و هماهنگ با لبها |
| پشتیبانی از زبان فارسی | ❌ ندارد | ✅ محدود دارد | ✅ بهبودیافته (تلفظ و ریتم بهتر) |
| دسترسی | فقط از طریق Google AI Studio در دسترس است | از طریق Gemini API در دسترس است | از طریق Gemini Pro و API قابل استفاده است |
| قابلیت چندصحنهای (Multi-Scene) | ❌ ندارد | ✅ دارد (در حد ابتدایی) | ✅ کاملاً فعال با کنترل دقیق صحنهها |
| هماهنگی گفتار با حرکت لبها | ❌ ندارد | ✅ دارد اما هنوز کامل نیست | ✅ بسیار دقیق با هماهنگی بالا |
| پشتیبانی از JSON Prompting | ✅ دارد اما محدود | ✅ کاملتر و دقیقتر | ✅ پیشرفته با کنترل پارامتری کامل |
🚀 مطالعه بیشتر: تولید محتوا در یوتیوب + نکاتی طلایی برای رشد و جذب مخاطب اگر قصد دارید خروجیهای VEO را برای یوتیوب یا ریلز استفاده کنید.
آموزش کار با VEO 3.1 در Gemini (گامبهگام)
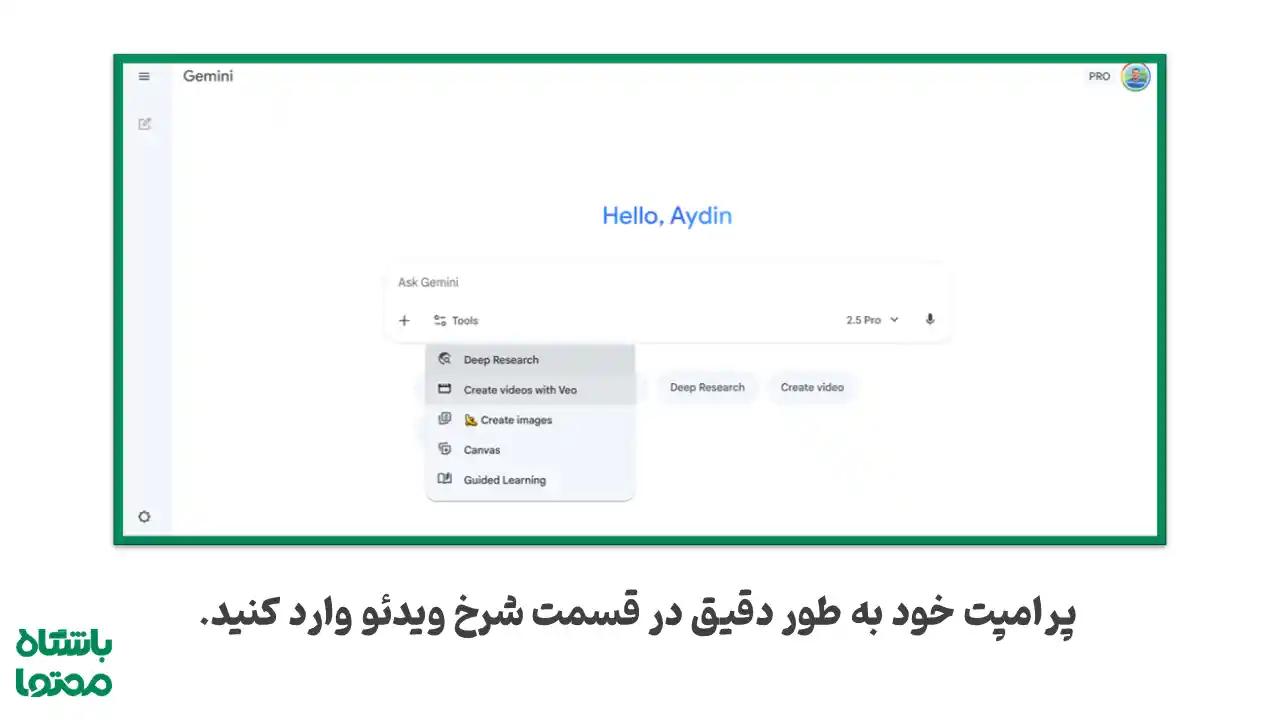
VEO 3.1 از طریق محیط Gemini App، بخش Create videos with Veo در منوی Tools و همچنین از طریق Gemini API و Flow در اختیار کاربران قرار گرفته است.
مرحله ۱: ورود به Gemini و فعالسازی مدل
- وارد حساب کاربری خود در Gemini Pro شوید.
- از منوی کناری یا نوار ابزار، روی Tools → Create videos with Veo کلیک کنید.
- در حال حاضر تنها مدل فعال، VEO 3.1 (Fast) است. این نسخه خروجیهایی سریعتر (۸ تا ۱۵ ثانیهای) با رزولوشن بالا ارائه میدهد.
- در باکس متنی ظاهرشده، پرامپت خود را بنویسید و میتوانید نوع ورودی را مشخص کنید:
-
- Text → Video (تولید ویدیو از توضیح متنی)
- Image → Video (تبدیل عکس به ویدیو)
- Multi-Scene Prompting برای ترکیب چند صحنه در یک خروجی
📘 نمونه پرامپت:
Create a short promotional video in Persian showing a designer working in a modern studio, with natural daylight and calm background music.
مرحله ۲: تولید ویدیو و کنترل خروجی
- پس از نوشتن پرامپت، روی Generate Video کلیک کنید.
- مدل شروع به ساخت ویدیو میکند و معمولاً در کمتر از ۳۰ ثانیه، خروجی اولیه را آماده میکند.
- در نسخهی فعلی (VEO 3.1 Fast) امکانات زیر در دسترس هستند:
- تولید گفتار و موسیقی: مدل میتواند صدا و گفتار طبیعی تولید کند و با حرکت لبها هماهنگ نماید.
- چندصحنهای (Multi-Scene): قابلیت ترکیب چند نما و زاویهی دوربین در یک ویدیو.
- بهبود بصری (Visual Enhancement): رندر نزدیک 4K، نورپردازی واقعگرایانه، و ترنزیشن نرم بین فریمها.
- پشتیبانی از زبان فارسی: تولید گفتار فارسی با دقت بیشتر نسبت به نسخهی قبلی.
- پس از پایان ساخت، میتوانید خروجی را دانلود، ذخیره یا مستقیماً در پلتفرمهای گوگل مثل Google Vids یا YouTube Shorts منتشر کنید.
نکات مهم و محدودیتهای فعلی
- دسترسی به VEO 3.1 هنوز در مرحلهی آزمایشی (Preview Access) است و تنها برای کاربران Gemini Pro یا Ultra فعال میباشد.
- ممکن است برخی قابلیتها (مثل صدای فارسی یا ویدیوهای طولانیتر) در همهی اکانتها فعال نباشد.
- سرعت تولید نسخهی Fast بالاست، اما در نسخهی کامل (API) امکان تنظیم رزولوشن، طول و صحنههای بیشتر نیز وجود دارد.
⚙️ بیشتر بدانید: ۲۱ ابزار رایگان هوش مصنوعی برای تولید آسان و سریع محتوا اگر به دنبال ابزارهای ویدیوساز و نویسنده خودکار هستید.
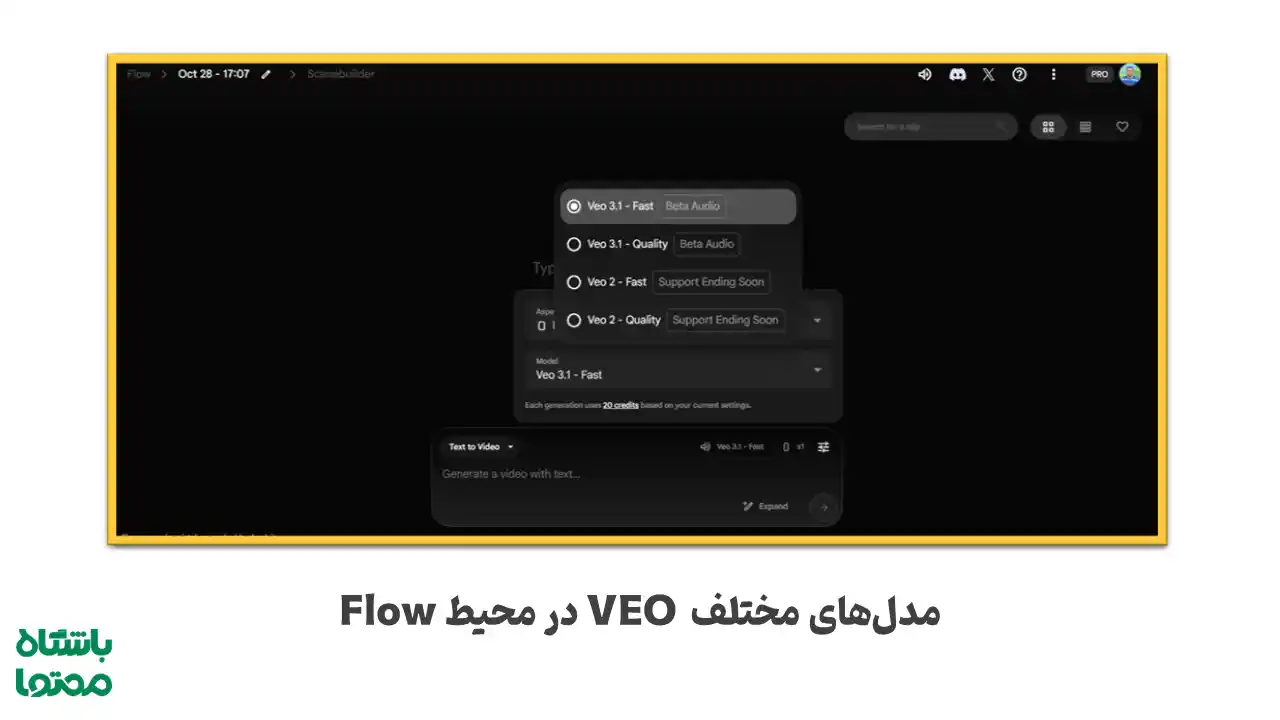
آموزش کار با VEO 2 و VEO 3.1 در Google Flow
در حال حاضر، مدلهای جدید گوگل از جمله VEO 3.1 به جز محیط جمینای از طریق محیط Google Flow در بخش Labs قابل دسترسی هستند و برای استفاده از آنها، نیاز به دسترسی API فعال یا حساب پولی Google Labs Pro دارید. در نسخه رایگان فقط امکان مشاهدهی پروژهها یا استفاده از مدلهای پایه فراهم است.
پس از ورود به سایت Flow:
- روی New Project کلیک کنید.
- از بخش مدلها، گزینهی VEO 3.1 – Fast یا VEO 3.1 – Quality (Beta Audio) را انتخاب کنید.
- نوع ورودی را مشخص کنید:
-
- Text to Video: تبدیل متن به ویدیو
- Frames to Video: ساخت ویدیو از چند فریم تصویری
- Ingredients to Video: ترکیب چند المان برای ساخت صحنه
📌 توجه: در حال حاضر اجرای این مدلها فقط با خرید اعتبار API یا اشتراک Pro فعال است و کاربران معمولی صرفاً میتوانند رابط کاربری را مشاهده یا تست اولیه انجام دهند.
ارتباط VEO 3 و Nano Banana 🍌
در کنار مدل ویدیوساز VEO 3 گوگل ابزار دیگری به نام نانو بنانا را نیز توسعه داده است. در حالی که VEO 3.1 برای ساخت ویدیو از متن یا تصویر استفاده میشود، Nano Banana یک مدل تصویرساز هوش مصنوعی است که وظیفهی تولید فریمهای ثابت و تصاویر خلاقانه را برعهده دارد.
این مدل معمولاً برای طراحی صحنهها، ساخت استوریبورد و تولید تصاویری استفاده میشود که بعداً میتوان آنها را در VEO 3.1 به ویدیوهای واقعی و متحرک تبدیل کرد. ترکیب این دو ابزار، روند تولید محتوای تصویری را کامل میکند: ابتدا تصویر با Nano Banana ساخته میشود و سپس همان فریم با VEO 3.1 جان میگیرد و به ویدیو تبدیل میشود.
به این ترتیب، اکوسیستم هوش مصنوعی گوگل از ایدهپردازی تصویری تا تولید ویدیوی نهایی را به شکلی یکپارچه در اختیار کاربران قرار میدهد.
🎥 حتماً ببینید: آموزش تولید محتوا بدون چهره با هوش مصنوعی (قدمبهقدم با Hedra AI) برای ساخت ویدیوهای آموزشی و تبلیغاتی بدون نیاز به حضور در تصویر.
کاربردهای عملی VEO 3 در تولید محتوا
در ادامه، برخی از کاربردهای عملی و متداول VEO3 را بررسی میکنیم:
۱. تیزرهای تبلیغاتی کوتاه با JSON
با استفاده از JSON Prompting میتوانید تیزرهای تبلیغاتی کوتاه و حرفهای را تنها با هوش مصنوعی طراحی کنید. این روش کنترل کامل بر صحنهها، ترنزیشنها و دیالوگها را فراهم میکند و به شما اجازه میدهد بدون نیاز به تجهیزات فیلمبرداری یا تدوین تخصصی، ویدیوهایی سفارشی و خلاقانه برای شبکههای اجتماعی، وبسایتها و کمپینهای بازاریابی با هوش مصنوعی تولید کنید.
۲. ویدیوهای خبری و خبرنگاری با صدای فارسی
با کمک این هوش مصنوعی میتوانید ویدیوهای خبری کوتاه با صدای فارسی طبیعی تولید کنید که گفتار آن کاملاً هماهنگ با تصویر است. این نوع محتوا برای رسانهها، کانالهای خبری آنلاین و اطلاعرسانی سازمانی بسیار کاربردی است و میتواند در ویدیوهای اطلاعرسانی سریع و شبکههای اجتماعی هم مورد استفاده قرار گیرد.
۳. محتوای آموزشی کوتاه و ریلز/شورت شبکههای اجتماعی
با استفاده از هوش مصنوعی VEO 3 میتوانید محتوای آموزشی کوتاه مخصوص شبکههای اجتماعی تولید کنید. این ویدیوها با توضیحات صوتی فارسی و طراحی تعاملی ساخته میشوند و برای انتشار در اینستاگرام، یوتیوب شورتز و سایر پلتفرمها کاملاً مناسباند. نتیجه، محتوایی جذاب، سریع و آموزشی است که به افزایش تعامل کاربران کمک میکند.
💡 پیشنهاد میکنیم بخوانید: چطور از هوش مصنوعی برای نوشتن مقالههای فارسی حرفهای استفاده کنیم؟ برای یادگیری تولید محتوای متنی طبیعی و حرفهای با ابزارهای AI.
نکات حرفهای پرامپتنویسی برای VEO 3
برای تولید ویدیوهای باکیفیت و حرفهای با VEO3 ، نحوه نوشتن پرامپت نقش بسیار مهمی دارد. پرامپت دقیق باعث میشود مدل بتواند صحنهها، حرکات، صدا و حتی زبان گفتار را مطابق نیاز شما تولید کند. در ادامه، نکات کلیدی و حرفهای پرامپتنویسی برای VEO3 را بررسی میکنیم:
1. واضح و مشخصبودن متن پرامپت
هرچه توضیحات صحنه، شخصیتها و محیط دقیقتر باشد و جزئیاتی مانند زاویه دوربین، نوع نور، حس فضا و زمان روز ذکر شود، خروجی نهایی طبیعیتر و نزدیکتر به واقعیت خواهد بود.
2. افزودن صدا و زبان گفتار
برای رسیدن به گفتاری واقعی و هماهنگ، باید در پرامپت مشخص کنید که زبان گفتار (Persian / English)، جنس صدا (مرد یا زن) و ریتم یا لحن موردنظر (آرام، رسمی، شاد و…) چگونه باشد تا مدل بتواند صوتی متناسب با فضای ویدیو تولید کند. مثال:
Include Persian voice narration explaining the scene, with a calm and friendly tone.
3. استفاده از JSON Prompting برای کنترل دقیق
برای تولید ویدیوهای تبلیغاتی یا صحنههای پیچیده، میتوانید جزئیات فریم، ترنزیشن، دیالوگها و موسیقی را در قالب JSON مشخص کنید. این روش به شما امکان میدهد تمام عناصر ویدیو را دقیقا مطابق نیاز تنظیم کنید و خروجی حرفهایتر باشد.
4. کوتاه و قابل فهمبودن دستورات
مدلهای ویدیوساز مانند VEO 3 بهتر است دستورات را مختصر اما دقیق دریافت کنند. از دادن جملات پیچیده و طولانی پرهیز کنید؛ جزئیات اصلی صحنه و صوت را بهصورت مرحله به مرحله بنویسید.
5. تست و اصلاح پرامپت
بعد از اجرای پرامپت، خروجی را بررسی کنید و در صورت نیاز، پرامپت را اصلاح و دوباره اجرا کنید. این روش باعث میشود ویدیوی نهایی هماهنگتر و با کیفیت بالاتر تولید شود.
اگر قصد دارید آموزش بیشتری برای این موضوع ببینید، پیشنهاد میکنیم مقاله آموزش پرامپت نویسی برای تولید محتوا با هوش مصنوعی را بخوانید.

چالشها و محدودیتهای استفاده از VEO 3
با وجود قابلیتهای چشمگیر VEO 3، هنوز چند محدودیت مهم وجود دارد که باید هنگام استفاده در نظر بگیرید:
- دسترسی محدود در ایران: برای ورود به Gemini یا استفاده از API، نیاز به VPN یا روشهای جایگزین دارید.
- نیاز به اینترنت پایدار: ساخت ویدیوهای باکیفیت و دارای صدا فقط با اتصال سریع و بدون قطعی ممکن است.
- ویرایش انسانی ضروری است: برای رسیدن به نتیجه حرفهای، معمولاً باید جزئیاتی مثل تلفظ فارسی، ترنزیشنها و هماهنگی صدا با تصویر را بهصورت دستی اصلاح کنید.
🎬 پیشنهاد مطالعه: ساخت ویدیوی لیپسینک با هوش مصنوعی؛ آموزش گامبهگام ساخت ویدیو از یک عکس ساده با ابزارهای رایگان AI را بخوانید.
جمعبندی
مدلهای ویدیوساز گوگل از VEO 2 تا VEO 3.1 مسیر تحول چشمگیری را طی کردهاند و نشان میدهند که تولید ویدیو دیگر به تخصصی میانرشتهای بین خلاقیت انسانی و هوش مصنوعی تبدیل شده است. اگر VEO 2 آغازگر تبدیل متن به ویدیو بود، VEO 3 و نسخهی جدیدتر آن یعنی VEO 3.1، مفهوم تولید محتوای هوشمند را با افزودن صدا، گفتار طبیعی و کنترل دقیق صحنهها با JSON Prompting متحول کردند.
با وجود محدودیتهایی مانند دسترسی در ایران یا نیاز به ویرایش انسانی، آیندهی تولید محتوا بهوضوح به سمت ترکیب خلاقیت انسان و قدرت پردازش مدلهای هوش مصنوعی حرکت میکند. برای آشنایی بیشتر با این رویکرد و یادگیری عملی، پیشنهاد میکنیم مقالهی آموزش تولید محتوا با هوش مصنوعی را نیز بخوانید.



